網路時代的來臨,一直默默耕耘的機器學習終於站上了舞台。隨之而來的深度學習以石破天驚的技術力展現在人們的眼前。
終於輪到重頭戲的部分。從今天開始正式邁入機器學習相關的篇章。
The field of study that gives computers the ability to learn without being explicitly programmed - Arthur Samuel(1959)
機器學習的定義是不需明確的程式設計給予電腦學習的能力。
不需明確的程式設計是指不用寫一堆條件判斷。而這邊說的學習,以常見的監督式學習來說就是讓機器找到從輸入到輸出的數學函數(function)。
傳統的電腦運算
輸入 + 函數 = 輸出
機器學習
輸入 + 輸出 = 函數
如果給你下面的題目,腦筋急轉彎試看看,答案會是多少呢?
1→3,2→6,3→9,4→?
機器學習也是和你一樣先從輸入和輸出找到了它們之間的關係。
也就是一個數學函數。3乘上輸入等於輸出。
我們透過機器學習找到了函數,就能代入資料預測答案。
所以簡單來說機器學習就是找到一個
數學函數,只要代入新的輸入,就可以給你想要預測的輸出。
機器從給予的樣本資料學習潛在的模式(函數)來預測答案,而樣本資料越多越能得到想要的學習結果(越正確的函數)。有點像是人類累積經驗一樣,經驗越多判斷就越準確。
就像剛剛的範例,如果題目只給 1→3 的話會因為樣本不足很難找到精確的函數。
1→3 有可能是,但也有可能是
早在第一次 AI 浪潮就有相關研究的機器學習,隨著1990年第一個網站的誕生,網路的普及導致資料爆發性地增加(BIG Data),讓機器學習的實用性也開始受到注目。
隨著資料的增加,機器學習在翻譯這一塊也有急速的進展。而所謂的統計式自然語言處理是指不考慮文法結構和意義,單純挑選數學統計上被這樣翻譯機率最高的結果,
比如說英文的 train ,如果句子也有出現 station(車站)的話,train 被翻成「火車」的機率最高。但是如果句子有 gym(健身房)的話,train 被翻成「訓練」的機率最高。
上述手法是利用語料庫(corpus)這種同時有中文和英文的大量單字資料來比對出機率。
可惜的是這種翻譯方法也有其限制,下面這句是很有名的例子。

如果是人類來翻譯的話,大概會翻成他用望遠鏡看到一位在花園的女性。但其實文法上來看,可以有好幾種意思。


而我們之所以可以翻譯出比較合理的句子,是因為「他用望遠鏡看到一位在花園的女性」的情況比較可能發生,符合他用望眼鏡時,偶然看到一位在花園的女性的情景。但電腦少了一般常識沒有辦法做出這樣的判斷。
世界知名的 Google 公司是統計式自然語言處理的代表之一,你可以試著用 Google 翻譯看看這一句的翻譯結果是什麼。
還記得深度學習是機器學習其中的一個分支,而深度學習可以自動擷取特徵嗎。
這個分支叫做人工神經網路或簡稱神經網路。
國中生物有教過人類的神經系統可以讓我們感應到冷熱,看得見,聽得見以及讓控制身體做出反應。神經系統裡的神經細胞又叫神經元(Neuron),大個有一千億個這麼多,彼此連結負責一層一層傳遞將身體五感接受的訊號傳遞給大腦。
那麼就有人問了,如果讓機器模仿人類的神經元,將其串起來成為人工神經網路,是不是就可能和人腦一樣思考了呢,而這個仿造出來的人工神經元叫做感知器 ,1958年由 Frank Rosenblatt 發表。
上課過的老師們都有提到使用這些名詞要特別注意,神經網路和感知器雖然是由人類的神經系統所啟發,但它們運作的細節和生物大腦無關,要小心避免誤會。
| 生物 | 人工仿造 |
|---|---|
| 神經系統 | 神經網路(人工神經網路) |
| 神經元 | 感知器 (人工神經元) |
簡單的感知器長這樣,比如說一個男生想預測自己在交友軟體上能不能配對成功。
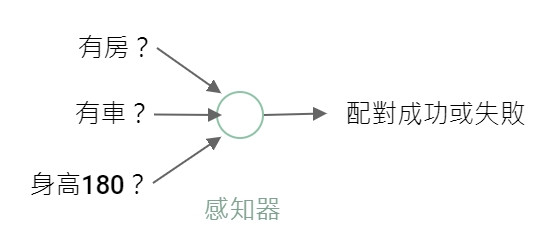
這個感知器內部在幹嘛,我們後面會提到,簡單來說就是做數學計算。
像這樣用感知器從配對成功的資料去找出一個數學函數,只要算出來的結果大於對方可接受的門檻,就有可能配對成功。
由幾個感知器串起來的簡單神經網路,處理步驟是這樣
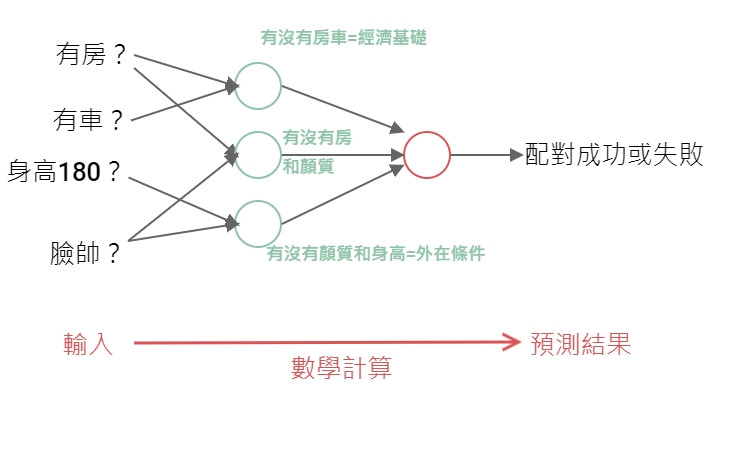
重要度用專業一點的講法叫權重(Weight)
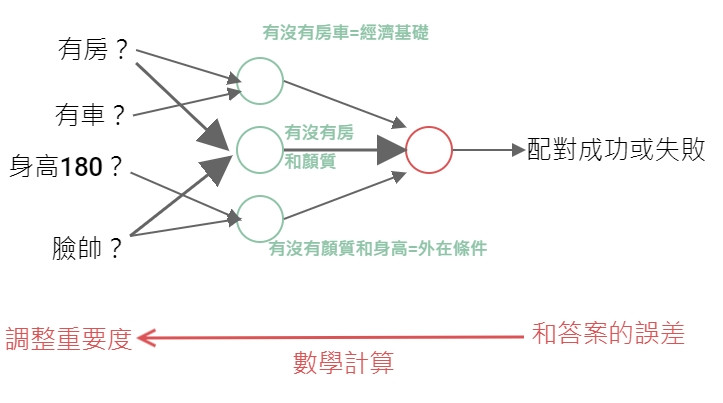
以這個假設的例子而言,我們可以看到有沒有房和顏質的重要度最高,反而是有沒有車或身高有沒有180公分沒有那麼重要不太影響配對結果,所以這兩個可能就不是重要的特徵。
這就是自動篩選出特徵的秘訣,然後像上面一樣作越多層理論上彈性越好結果可以更精細。但是越多層會有一個數學難題,就是越多層往回做重要度的調整會越來越不準。後來解決了這個數學難題,可以越做越多層(越來越深),準確率越來越高的神經網路,其實就是深度學習。
雖然神經網路和深度學習基本上是一樣的東西,但是以現實面來看深度學習聽起來比較酷,補助費比較要得到。AI 寒冬時只要是 AI 相關的名詞常會被人認為是騙錢的東西,神經網路也經歷過那個時期。
ILSVRC(大型視覺辨識競賽)是一個由 ImageNet 主辦,使用電腦辨識圖片的全球性比賽。經由辨識圖片是貓咪,人還是建築物等,看誰的辨識錯誤率最低。當時由機器學習來辨識圖片已經是主流,但因為機器學習的特徵是由人來決定,是屬於專家的知識範疇,各機構都在不斷嘗試錯誤中找出好的特徵,才好不容易降低一丁點錯誤率。
就在這樣爭取百分之零點幾誤差的世界裡,2012年第一次參賽的多倫多大學 SuperVision 橫空出世。以16% 錯誤率和第二名東京大學(26%)拉開非常大的差距, 壓倒性地取得了勝利!
多倫多大學致勝的關鍵,是採用該所大學的 Geoffrey Hinton 教授從2006年展開的深度學習技術,不再由人類來設計特徵,而是讓機器從資料裏頭自動取得特徵再分類圖片。從此機器學習又往自動化更前進一步。
如此令人驚愕的成果在世界各地捲起了旋風,也讓深度學習一詞變成最火熱的話題。
ILSVRC是縮寫,全名是 ImageNet Large Scale Visual Recognition Challenge
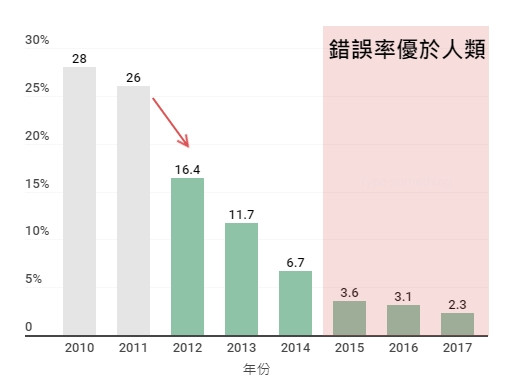
2012年採取深度學習之後可以看到一口氣下降了快10%,之後逐年降低,2015年更是打破人類錯誤率4%的極限,達到了比人類更優秀的識別率。
| 年份 | 獲勝隊伍 | 模型名 | 手法 |
|---|---|---|---|
| 2012 | SuperVision | AlexNet | 8層,6千萬個參數 |
| 2014 | GoogLeNet | 22層 Inception | |
| 2015 | Microsoft | ResNet | 152層 Skip connection |
| 2017 | Momenta | SEnet | Attention |
深度學習的深度每年都不斷的增加,技術也一直推陳出新。
常遇到有人把參賽隊伍名誤當成模型名稱...

